




 点击刷新
点击刷新

前言
Ajax,全称为 Asynchronous JavaScript and XML,是利用 JavaScript 在保证页面链接不改变的情况下,滑动某一区域会不断地出现新的数据,是与服务器交换数据并更新部分网页的技术。
一、Ajax是什么?
Ajax这个术语源自描述从基于 Web 的应用到基于数据的应用。
Ajax 不是一种新的编程语言,而是一种用于创建更好更快以及交互性更强的Web应用程序的技术。
Ajax 在浏览器与 Web 服务器之间使用异步数据传输(HTTP 请求),这样就可使网页从服务器请求少量的信息,而不是整个页面。
二、Ajax案例实战
案例分析
1、用 chrome 浏览器打开链接(https://weibo.com/nba)按下 F12 就会打开检查界面

2、然后点击 Network ,再点击 Fetch/XHR,(这是为筛选出一带XHRXMLHttpRequest(XHR)是一个构造函数,对象用于与服务器交互。通过 XMLHttpRequest 可以在不刷新页面的情况下请求特定 URL。即允许网页在不影响用户操作的情况下,更新页面的局部内容。可以用于获取任何类型的数据。)最后点击刷新,重新加载数据。
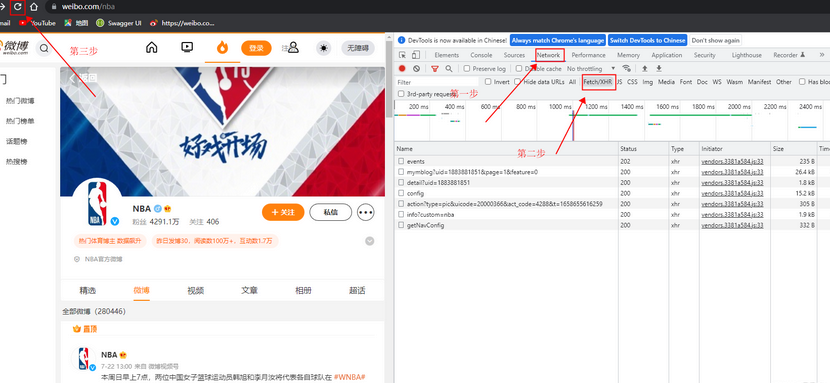
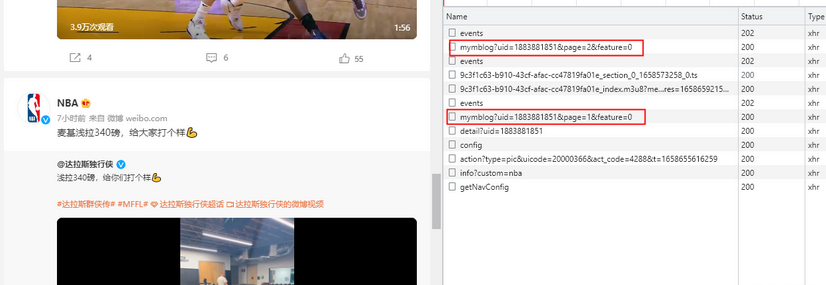
3、通过不断的滑动微博发布的内容区域,让其对数据进行加载,右边的检查界面也会出现新的数据。然后找到那些相以的,又带有微博发布内容数据的请求
这两个请求是带的微博发布内容数据的请求,两个请求的不同之处就 page 的值不一样,
编写请求头
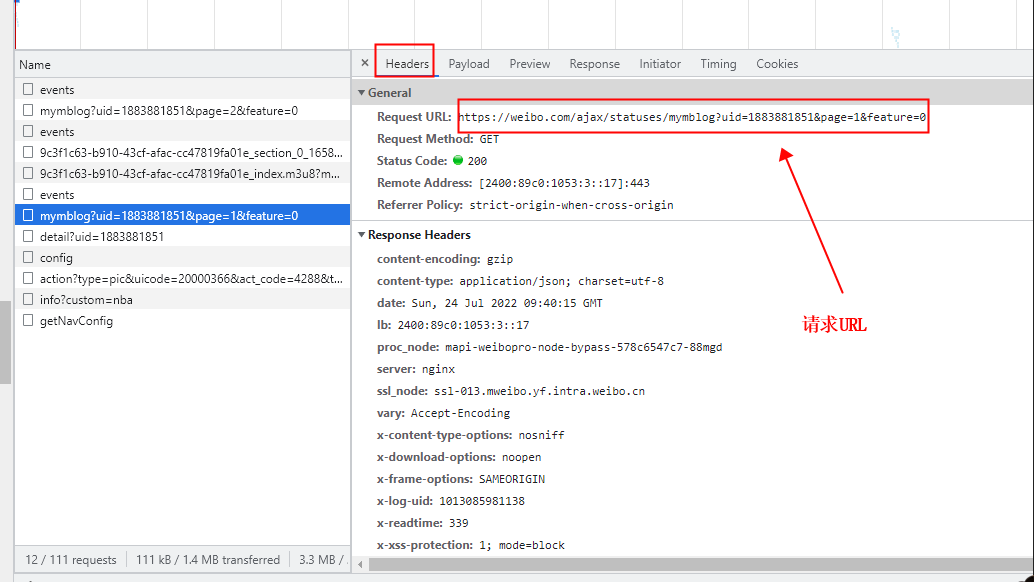
1、点击带的微博发布内容数据的请求,找到请求url
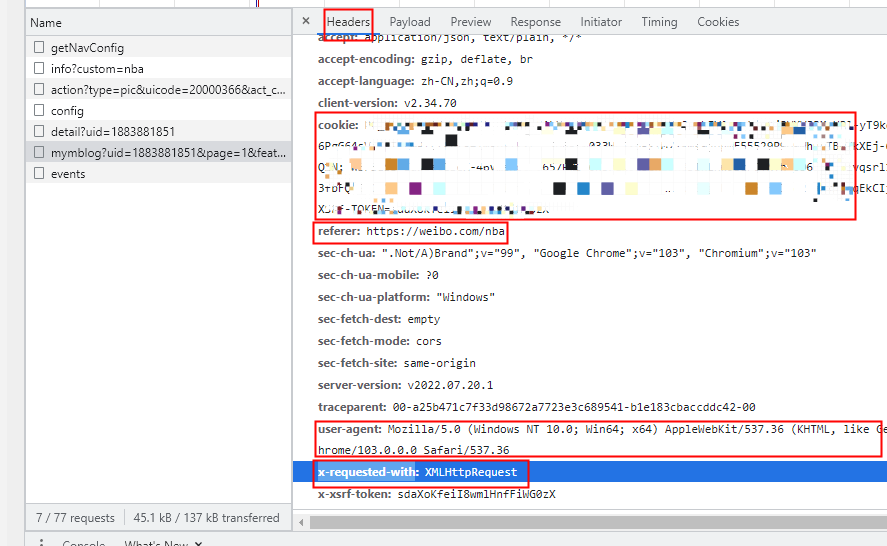
2、要向服务器发送的几个必要参数 cookie(打开请求头看到coojie是什么就复制什么)referer 、user-agent、x-requested-with
代码如下(示例):
# 写入请求头
headers = {
'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
# 根据自己的情况补充cookie
'cookie': '',
'referer': 'https://weibo.com/nba',
'sec-ch-ua-platform': '"Windows"',
'user-agent': UserAgent().chrome,
'x-requested-with': 'XMLHttpRequest',
}
查看请求URL返回的数据
请求URL返回的数据一般都 json格式 的数据,点击 Preview 就可以查看到返回的数据了,而我们想要数就在 list 里面
对json数据进行处理
代码如下(示例):
def Get_the_data(url):
json_data = scrape_page(url)
# json.dump(json_data, open('./xx.json', 'w', encoding='utf-8'),
# ensure_ascii=False, indent=2)
items = json_data.get('data').get('list')
# 历遍 list
for item in items:
# 获取时间
Publish_time = item.get('created_at')
# 获取文本
# 判断是否存在这个键
if 'text_raw' in item:
content = item.get('text_raw')
else:
content = item.get('page_info').get('media_info').get('next_title')
# 获得视频
# 声明变量
global video_url
if 'page_info' in item:
if 'media_info' in item.get('page_info'):
if 'h5_url' in item.get('page_info').get('media_info'):
video_url = item.get('page_info').get(
'media_info').get('h5_url')
else:
video_url = None
# 获取相片
if 'pic_infos' in item:
# 存放相片url的列表
photo_urls = []
for photo in item.get('pic_infos'):
if 'original' in item.get('pic_infos').get(photo):
photo_url = item.get('pic_infos').get(
photo).get('original').get('url')
photo_urls.append(photo_url)
else:
photo_urls = None
# 获取转发次数
reposts_count = item.get('reposts_count')
# 评论数
comments_count = item.get('comments_count')
# 点赞次数
attitudes_count = item.get('attitudes_count')
wb_data = {
'发布时间': Publish_time,
'发布内容': content,
'视频链接': video_url,
'相片链接列表': photo_urls,
'转发次数': reposts_count,
'评论数': comments_count,
'点赞次数': attitudes_count
}
logging.info('get detail data %s', wb_data)
logging.info('saving data to mongodb')
save_data(wb_data)
logging.info('data saved successfully')
保存数据到Mongodb
代码如下(示例):
# pymongo 用来链接mongodb数据库的
import pymongo
# pymongo有自带的连接池和自动重连机制,但是仍需要捕捉AutoReconnect异常并重新发起请求。
from pymongo.errors import AutoReconnect
from retry import retry
'''
AutoReconnect:捕捉到该错误时进行重试,这个参数可以是一个元组,里面放上多个需要重试的条件
tries:重试次数
delay:两次重试的间隔时间
'''
@retry(AutoReconnect, tries=4, delay=1)
def save_data(data):
"""
将数据保存到 mongodb
使用 update_one() 方法修改文档中的记录。该方法第一个参数为查询的条件,第二个参数为要修改的字段。
upsert:
是一种特殊的更新,如果没有找到符合条件的更新条件的文档,就会以这个条件和更新文档为基础创建一个新的文档;如果找到了匹配的文档,就正常更新,upsert非常方便,不必预置集合,同一套代码既能用于创建文档又可以更新文档
"""
# 存在则更新,不存在则新建,
collection.update_one({
# 保证 数据 是唯一的
'发布时间': data.get('发布时间')
}, {
'$set': data
}, upsert=True)
多线程引入
代码如下(示例):
# 多线程的引入
import multiprocessing
if __name__ == '__main__':
# 引入多线程
pool = multiprocessing.Pool()
wb_urls = []
for page in range(1, 150):
urls = WB_URL.format(uid=UID, page=page)
wb_urls.append(urls)
# map()函数。需要传递两个参数,第一个参数就是需要引用的函数,第二个参数是一个可迭代对象,它会把需要迭代的元素一个个的传入第一个参数我们的函数中。因为我们的map会自动将数据作为参数传进去
# 传入一个url列表,Get_the_data方法每次只能获取一条url
pool.map(Get_the_data, wb_urls)
# 关闭mongodb连接
client.close()
# 关闭进程池,不再接受新的进程
pool.close()
# 主进程阻塞等待子进程的退出
pool.join()
总结
通过对爬取NBA微博数据案例来体会 Ajax 分析和爬取的基本流程,由于Ajax 接口大部分都是以 JSON 的格式返回数据,在一定程度上减少了对数据提取的工作量。
© 著作权归作者所有
发表评论


