




 点击刷新
点击刷新

python爬取中国天气网天气图标
准备工作
- 天气预报图例网址:
http://www.weather.com.cn/static/html/legend.shtml - 安装requests:
pip install requests
网页分析
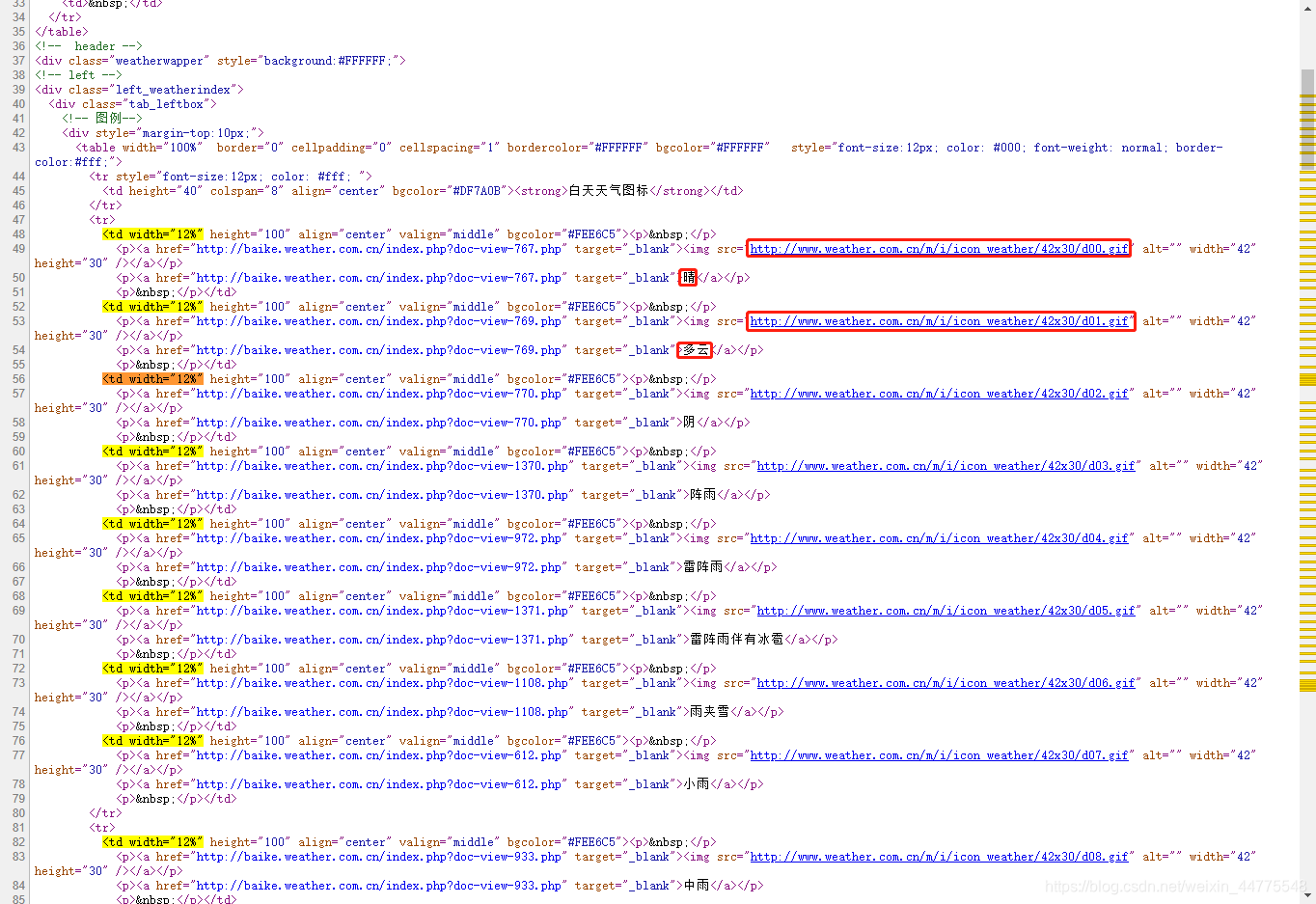
- 打开网页,可以看到图标有很多,而且分白天和夜间,我们要把图标保存到本地,并且图标名字要对应

- 右键查看网页源代码,发现图标和名称都放到 `<td width="12%" ...` 的 **td** 标签下,而我们要做的就是提取其中的图片和名称
编写代码
爬取网页
import requests
url = 'http://www.weather.com.cn/static/html/legend.shtml'
def getPage():
# 请求头
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5383.400 QQBrowser/10.0.1313.400"}
res = requests.get(url, headers)
# 手动指定字符编码为utf-8
res.encoding = 'utf-8'
print(res.text)
return res.text
if __name__ == "__main__":
getPage()- requests库的使用方法非常简单,requests.get(网页url) 就可以拿到网页内容了,但是为了模拟浏览器请求,最好还是加上请求头headers
-
requests响应内容:
res.encoding:可以拿到当前的编码格式,也可以设置编码格式res.text:字符串响应体,这里就是网页的源代码res.content:二进制的响应体,如果是图片需要用到r.encoding #获取当前的编码 r.encoding = 'utf-8' #设置编码 r.text #以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码。 r.content #以字节形式(二进制)返回。字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩。 r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None r.status_code #响应状态码 r.raw #返回原始响应体,也就是 urllib 的 response 对象,使用 r.raw.read() r.ok # 查看r.ok的布尔值便可以知道是否登陆成功 r.json() #Requests中内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛异常 r.raise_for_status() #失败请求(非200响应)抛出异常 - 爬取下来的网页,打印出来时发现中文乱码了,因此需要指定编码方式为
utf-8
提取图片和名称
import re
# td正则
wrapReg = r'<td width="12%"[^>]*>.*?</td>'
# 图片url正则
imgReg = r'<img src="(.*?)"'
# 天气名称正则
nameReg = r'<a[^>]*>([^>]*?)</a>'
# 颜色正则
colorReg = r'bgcolor="(.*?)"'
def run():
# 爬取网页
text = getPage()
# 拿到td标签里的内容
lis = re.findall(wrapReg, text, re.S|re.M)
for item in lis:
bgcolor = re.findall(colorReg, item, re.S|re.M)
imgUrl = re.findall(imgReg, item, re.S|re.M)
nameStr = re.findall(nameReg, item, re.S|re.M)
if imgUrl and len(imgUrl) > 0 and nameStr and len(nameStr) > 0 and bgcolor and len(bgcolor) > 0:
print('------------')
print(imgUrl[0], nameStr[0], bgcolor[0])- 首先我们拿到网页的源码
res.text -
然后正则匹配包裹图片和名称的
td标签,这里需要匹配包含 td 元素。为什么?后面会有说明re.findall(pattern, string, flags=0)
返回string中所有与pattern匹配的全部字符串,返回形式为数组wrapReg = r'<td width="12%"[^>]*>.*?</td>'
1.一个.就 是匹配除 n (换行符)以外的任意一个字符
2.*前面的字符出现0次或以上
3..*贪婪,匹配从.*前面为开始到后面为结束的所有内容
4..*?非贪婪,遇到开始和结束就进行截取,因此截取多次符合的结果,中间没有字符也会被截取
5.(.*?)非贪婪,与上面一样,只是与上面的相比多了一个括号,只保留括号的内容,在这里,如果加上括号,则只返回td标签的子元素,不返回td标签本身修饰符 描述 re.I 使匹配对大小写不敏感 re.L 做本地化识别(locale-aware)匹配 re.M 多行匹配,影响 ^ 和 $ re.S 使 . 匹配包括换行在内的所有字符 re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 - 循环 td 标签列表,继续用正则匹配 td 标签里的
图片url和天气名称,td 标签下还有 p > a 标签包裹,图片只需要img 标签 src 属性里面的内容,而天气名称是拿整个 a 标签里的内容,这里注意看括号的位置

- 最后就可以根据图片url和天气名称下载保存图片了,但是还有个问题需要注意,把网页拉到下面发现,td 标签里面可能是空的,因此需要判断是否有正确匹配才继续



- 另外,还需要匹配一个 td 的属性,
bgcolor,这个也会在后面说明
下载保存图片
# 后缀正则
suffixReg = r'\.([^.]*?)$'
def saveFile(url, name, bgcolor):
# 获取后缀
suffix = re.findall(suffixReg, url)
# 下载文件
res = requests.get(url)
# 根据bgcolor区分白天和黑夜文件路径
filePath = 'day/' if bgcolor == '#FEE6C5' else 'night/'
print('filePath --> ', filePath)
# 文件名
fileName = filePath + name + '.' + suffix[0]
with open(fileName, 'wb') as f:
# 保存文件
f.write(res.content)
f.close- 前面提到,为什么要匹配
包含 td 标签以及bgcolor有啥用?去掉 td 标签本身不是更简洁?这是因为白天和夜间的天气名称是一样的,如果不分白天夜间,那么保存了白天的图片,程序执行到保存夜间图片的时候,会把白天的图片替换掉。而白天和夜间的图片和名称正则都是相同的,有什么办法来区分白天和黑夜? - 回去看源代码,发现了白天和黑夜 td 标签有个属性,白天的
bgcolor="#FEE6C5",而夜间的bgcolor="#D8E7F8",因此就可以用这个属性来区分,分别将白天图片保存到day目录下,夜间图片保存到night目录。需要在当前路径下新建day 和 night 文件夹,否则会报错 - 另外,保存图片的时候只有图片名称,没有图片后缀,而图片url又刚好有图片的后缀,所以就可以根据图片url的后缀来确定文件的后缀
© 著作权归作者所有
举报
发表评论
0/200


